Danish version: http://qed.dk/jeppe-cramon/2014/03/13/micro-services-det-er-ikke-kun-stoerrelsen-der-er-vigtigt-det-er-ogsaa-hvordan-du-bruger-dem-del-2/
Part 1 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 3 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 4 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 5 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 6 – Service vs Components vs Microservices
Text updated the 23rd of June 2021
In Micro services: It’s not (only) the size that matters, it’s (also) how you use them – part 1, we discussed how the number of lines of code is a very poor measure for whether a service has the correct size and it’s totally useless for determining whether a service has the right responsibilities.
We also discussed how using 2 way (synchronous) communication between our services results in tight coupling and other annoyances, amongst other things communication related coupling, because data and logic often aren’t in the same service.
2 way (synchronous) communication between services also causes:
- Higher latency due to network communication
- Contractual-, data– and functional coupling
- Layered coupling, because persistence logic often isn’t in the same service that owns the business logic
- Temporal coupling, which means that our service can not operate if it is unable to communicate with the services it depends on
- Lower services autonomy and less reliability, because our service depends on other services to perform its job
- All of this also introduces the need for complex compensation logic due to the lack of reliable messaging and coordinating transactions.
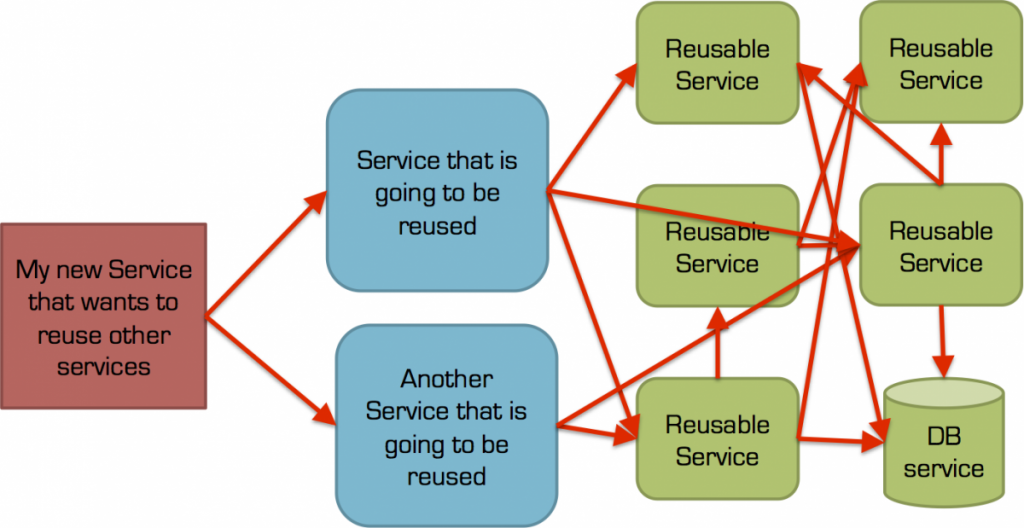 Reusable service, 2 way (synchronous) communication and coupling
Reusable service, 2 way (synchronous) communication and coupling
Worst case, If we combine (synchronous) 2 way communication with nano- / micro-services, modelled according to e.g. the rule 1 class = 1 service, we have basically returned to the 1990s where Corba and J2EE/EJB’s and distributed objects ruled.
Unfortunately, it seems that new generations of developers, who did not experience distributed objects and therefore haven’t yet realized how bad an idea it was to overuse this, is bound to repeat history.
This time we have just switched technologies like RMI or IIOP out with HTTP+JSON instead.
Jay Kreps summed up the common Micro Service approach, using two way communication, very aptly:

Jay Kreps – Microservice == distributed objects for hipsters (what could possibly go wrong?)
Just because Micro Services tend to use HTTP/JSON/REST/GraphQL doesn’t remove the disadvantages of remote communication. The disadvantages, that newcomers to distributed computing easily overlook, are summarized in the 8 fallacies of distributed computing:
They believe:
- The network is reliable
However, anyone who has tried losing the connection to a server, a database or to the Internet will know this is a fallacy. Even in a perfect setup, you will be able to experience network crashes or I/O exceptions/errors from time to time - Latency is zero
It’s easy to overlook how insanely expensive it is to make a network call compared to making an equivalent in-process call. With a network latency is measured in milliseconds instead of nanoseconds. The more calls we executed sequentially over the network, the worse the combined latency will be. - Bandwidth is infinite
In fact network bandwidth, even on a 10 GBit network, is much lower than if the same call was made in-memory/in-process. The more data being sent and the more calls being made, due to tiny services, the greater the impact of the more limited bandwidth becomes - The network is secure
Saying NSA should cover why this is a fallacy? - Topology doesn’t change
Reality is different. Deployed Services will experience a constantly changing environment. Old servers are upgraded or moved, and if necessary also changing IP address, network equipment is changed or reconfigured, firewalls, change configuration, etc. - There is one administrator
In any large-scale installation there will be several administrators: Network administrators, Windows admins, Unix admins, DB admins, etc. - Transport cost is zero
For a simple example of why this is a fallacy we don’t need to look any further than the cost of serializing / deserializing between internal memory representation and JSON / XML / Protobuf / Avro / … - The network is homogeneous
Most networks consist of various brands of network equipment, which supports various protocols and communicate with computers with different operating systems, etc.
The review of the 8 fallacies of distributed computing is far from complete. If you are curious, Arnon Rotem-Gal-Oz has made a more thorough review (PDF format).
What is the alternative to 2 way (synchronous) communication between services?
The answer can among others be found in Pat Hellands “Life Beyond Distributed Transactions – An Apostate’s Opinion” (original article from 2007) / “Life Beyond Distributed Transactions – An Apostate’s Opinion” (updated and abbreviated version from 2016)
In his article Pat discusses that grownups do not use Distributed transactions to coordinate updates across transaction boundaries (e.g. across databases, services, etc.).
There are many good reasons not to use distributed transactions, among them are:
- Transactions lock resources while they are active
Services are autonomous , so it’s clear that if through a distributed transaction, another service is allowed to lock resources in your service, it will be a clear violation of your services autonomy - A service can NOT be expected to complete its processing within a specified time interval – it is autonomous and therefore in control of how and when it wants to perform its processing. This means that the weakest link (Service) in a chain of cross service calls/updates determines the strength of the entire chain.
- Locking, depending on the type of lock, potentially keeps other transactions from completing their job
- Locking does not scale
If a transaction takes 200 ms and e.g. holds a table lock, then the service can maximum be scaled to 5 simultaneous transactions per second. It does not help to add more machines as this doesn’t change the time lock is kept by a single transaction - 2 phase / 3 phase / X phase commit distributed transactions are fragile per design.
So even though X phase commit distributed transactions, at the expense of performance (yes X phase commit protocols are expensive), solves the problem with coordinating updates across transactional boundaries, there are still many error scenarios where an X phase transaction is left in an unknown state.
E.g . if a 2 phase commit flow is interrupted during the commit phase, it essentially means that some transaction participant has committed their changes while others have not.
If just a single participant fails or is unavailable during the commit phase, then you’re left on deep water without a boat – see the drawing below for the 2 phase commit flow 2 phase commit protocol flow
2 phase commit protocol flow
So if the distributed transactions isn’t the solution, then what is the solution?
The solution is in three parts:
- One part is how we split our data between services
- How do we identify our data within services
- And how we communicate between our services
How should we split our data between services?
According to Pat Helland, data must be collected in pieces called entities.
These entities should be limited in size, such that after a transaction they are consistent.
This requires that an entity is not greater than it can fit on one machine. If we need to split the data across machines we would have to use distributed transactions to ensure consistency, which is what we want to avoid in the first place.
It also requires that the entity is not too small. If it’s too small then we would experience many use cases, where we would need to update multiple entities across different services in order to complete the use case (a simple example would be storing the Order object in one service but all the individual OrderLines objects, associated with the Order, in another Service). This would bring us right back to the case, where we would need to coordinate updates across services by e.g. using distributed transactions to ensure a consistent system.
Rule of thumb is: one transaction involves only one entity.
Let us look at an example from the real world
In a previous project I was faced with I would call a textbook example of how misguided reuse ideals and micro splitting of services undermined service stability, transactional guarantees, coupling and latency.
The customer planned to ensure maximum reuse for two domain concepts, respectively Legal Entities and Addresses; where addresses covered everything that could used to identify a legal entity (and most likely everything else on earth), such as home address, work address, email, phone number, mobile number, GPS location, etc.
To ensure maximum (speculative) reusability they created a service for each entity type, which we basically could call Entity services as they’re basically a database with a thin API on top:
- Legal Entity Micro Service
- Address Micro Service
To create a new Legal Entity the create use case involved creating a Legal Entity together with one or more Addresses. To support this use case they needed a Services that could coordinate the calls to the services operations part of the use case. In the layered SOA terminology this is often called a Task service.
For this task they introduced the Legal Entity Task Service, which was tasked with coordination of the classical CRUD (Create Read Update Delete) use cases. They could have chosen to let the Legal Entity Micro Service take the role of coordinator, but that wouldn’t have solved the fundamental transactional problem that we’re going to discuss here.
To complete the Create Legal Entity use case, the Legal Entity Task Service‘s CreateLegalEntity() method would:
- Create a Legal Entity, such as a Person or a Company, by calling the CreateLegalEntity() method in the Legal Entity Micro Service.
- Then for each addresses defined in input to CreateLegalEntity( ) in the Legal Entity Task Service, it would need to call CreateAddress() in the Address Micro Service.
- Creating an Address resulted in an AddressId that was returned from the CreateAddress() method in Address Micro Service.
- This AddressId afterwards had to be associated with the LegalEntityId that was returned from the CreateLegalEntity( ) method of the Legal Entity Micro Service
- Associating the Address with the Legal Entity happened by calling the AssociateLegalEntityWithAddress() in Legal Entity Micro Service for each combination of LegalEntityId and AddressId.
The attentive reader will already have noticed some challenges due to LegalEntityId and AddressId being assigned by the Service operations and NOT the caller. The service assigned id design further increases the work the Legal Entity Micro Service and Address Micro Service operations have to perform, as they now also need to perform more advanced duplication checks.
A better design would have allowed the caller/client to specify the LegalEntityId/AddressId as part of the method signature/payload. This would have made the deduplication much easier and have ensured that the operations were easily idempotent by design.

Bad Microservices – Create scenario
From the sequence diagram above, it should clear that there is a high degree of coupling (of all types).
If the Address Micro service does not respond, then you cannot create any legal entities.
The latency of this solution is also high due to the high number of remote calls. Some of the latency can be minimized by performing some of the calls in parallel, but it is sub-optimization of a fundamental poor solution and our transaction problem is still the same:
If just a single of the CreateAddress() or AssociateLegalEntityWithAddress() calls fail we’re left with a nasty problem:
- Say we have managed to create a Legal Entity and now one of CreateAddress() calls fail.
Unless we add compensation logic to the Task service operation, then we’re left with an inconsistent system, because not all of the data we intended to create was stored. - The case could also have been that we created our Legal Entity and all the Addresses, but somehow not all the addresses were successfully associated with the legal entity. Again we’re faced with an inconsistent system.
This form of orchestration places a heavy burden on the CreateLegalEntity() method in the Legal Entity Task Service. This method is now responsible for retrying any failed calls or performing a clean up after them, also known as compensation.
There are also many potential failures for the compensation logic and the cleanup logic:
- Maybe one of the cleanups failed and what do we do then?
- What if the CreateLegalEntity() method in the Legal Entity Task Service is in the process of retrying a failed call or it’s in the process of performing a clean up when the physical server it runs on is turned off or crashes?
- Did the developer remembered to implement the CreateLegalEntity() method in the Legal Entity Task Service, so it remembers how far it was and can resume its work when the server is started.
- Did the developer of CreateLegalEntity(), CreateAddress() or AssociateLegalEntityWithAddress() methods ensure that the methods are idempotent, so any call to them can be retried several times without risking double creation or double association?
The transactional problems can be solved by looking at the use cases and re-evaluating the reuse thesis
The design of the LegalEntity and Address services were the result of design by committee. A team of architects had designed a logical canonical model and from this design, they had decided what was reusable and thus what should be elevated to services. The problem with this approach is that a canonical data model does not take into account how the data is used, i.e. the different use cases that use this data. The reason this is a problem, is that the way data is changed/created directly determines our transaction boundaries, also known as our consistency boundaries.
Data that is being changed together in a transaction / use case, should as a rule of thumb, also belong together both data wise and ownership wise.
Our rule of thumb can therefore be expanded to: 1 use case = 1 transaction = 1 entity.
The second mistake they made was to view the Legal entities’ addresses as a shared concept that other Services could and should reuse. You could say that their reuse focus caused everything that smelled of an address to be shoehorned into the Address service. The hypothesis was that if all other Services used the Address service and a city suddenly changed name or postal code, then you could fix it in one place. The latter was perhaps a valid reason to centralize due to this very specific and very rare use case, but it had high costs for everything else.
The data model looked something like this (a lot of details omitted):
 Bad micro service data model
Bad micro service data model
As shown in the model, the association between LegalEntity and Address is shared directed association indicating that two LegalEntities can share an Address instance. This was again born out of the wish for a high degree of reuse. However this reuse never came to fruition, so the association was actually more of a composite directed association, indicating a parent-child relationship, meaning that there’s for example no need to store an Address for LegalEntity after the LegalEntity has been deleted.
The parent-child relationship shows that LegalEntity and Address belongs closely together, because they’re created together, changed together, read together and they’re used together.
What this means is that instead of having two entities, we really only have one major entity, the LegalEntity with one or more Address’ associated with it.
This is where Pat Hellands Entity vocabulary can benefit from Domain Driven Design’ (DDD) more rich language, which includes:
- Entity – which describes an object that is defined by its identity and not its data. Examples: A Person has a Social Security number, a Company has a VAT number, etc.
- Value Object – which describes an object that is defined by its data and not its identity. Examples: an Address, a Name, or an Email address. Two value objects, of the same type, with the same value are said to be equal. A value object never exists alone, it always exists as part of a relationship with an Entity. The value object, so to speak enriches the Entity with its data.
- Aggregate – is a cluster of coherent objects with complex associations. An Aggregate is used to ensure invariants and guarantee the consistency of the relationship between the objects that are part of it.
An Aggregate can be used to control locking and guarantee transactional consistency in the context of distributed systems.- An Aggregate chooses an Entity to be the root and control access to objects within Aggregate through this root, which helps it to control invariants among other things.
The root is called the Aggregate Root. - An Aggregate is a unique identifiable by its ID (usually a UUID/GUID)
- Aggregates refer to each other by their ID – they NEVER use memory pointers, remote calls or Join tables (which we will return to in the next blog post)
- An Aggregate chooses an Entity to be the root and control access to objects within Aggregate through this root, which helps it to control invariants among other things.
From this description we can determine that what Pat Helland calls an Entity is called an Aggregate in DDD jargon. DDD’s language is more rich, so I will continue to use DDD’s naming.
If you are interested in reading more about Aggregates I can recommend this Gojko Adzic article.
From our use case analysis (LegalEntity and Address are created and changed together) and the use of DDD’s jargon (LegalEntity is an Aggregate Root/Entity and Address is a value object), we can now redesign the data model (also known as domain model):

LegalEntity Microservice – better model
With the design above the AddressId has disappeared from the Address, since a Value Object doesn’t need one.
This bring us to section two
How do we identity our data within a Service?
According to Pat Helland each aggreate should uniquely identifiable by an ID, using for instance a UUID / GUID.
With this new design the LegalEntity is identifiable using a LegalEntityId and this the identifier we will refer to when we communicate with LegalEntity micro service.
Conclusion
With the redesign we have made the Address service obsolete and all that is left is the “Legal Entity Micro service”:
Better LegalEntity Microservice
With this design our transaction problem has completely disappeared because there is only one service to talk to in this example.
There is still much that can be improved here and we have not yet covered how to communicate between services to ensure coordination and consistency across services when our processes / use-cases cut across multiple aggregates / services.
This blog post is already getting too long, so I’ll wait and cover this next blog post.
Until then, as always, I’m interested in feedback and thoughts 🙂

Thanks heaps for putting the time into writing this. I love how you’re bringing the language of DDD into microservice architecture design. I’m finding that deciding where data should live and how to share it is one of the really hard problems, but this really helped.
LikeLike
Great post! I have a few comments here as well:
1) When I teach SOA to IT professionals, I talk a lot about service autonomy. One thing I mention is that we should strive to improve service autonomy. However, it’s natural that a service may depend on external elements. If service A makes a REST or SOAP call to service B, that call decreases service A’s autonomy. If service A accesses a central database, this access decreases its autonomy. If service A sends emails, the interaction with the smtp host negatively affects the service’s autonomy. If service A sends a message to a JMS queue in a separate process or server, that interaction also decreases the service’s autonomy. Moreover, service autonomy can be assessed but hardly can be measured objectively.
Having said that, I feel unease with some “absolute” statements in the text. For example:
– where you say “The fact that our service depends on other services undermines its autonomy and makes it more unreliable”, I would rather say “The fact that our service depends on other services decreases its autonomy and makes it less reliable”
2) I never heard of a “1 class = 1 service” rule and I don’t think it’s a goal to try. I worked in one Corba project in the late 90s. In the early 2000s I was a J2EE consultant and EJB instructor for Sun. These technologies were (are) complex and troublesome for many reasons, but an EJB service would typically have the EJB class (e.g., @Stateless) that would call a graph of other classes.
3) I find the following statement unclear: “This requires that an entity is not greater than it can fit on one machine”. Are you talking about the data in the database or about the data/entity services? How does this idea map to the example that follows? Are Legal Entity and Address separate entities? Size-wise, do they belong on one machine?
4) When I teach, I tell people that distributed transactions are source of headache. Even if the transaction participants, the network, the database connections are robust and reliable, one out of N transactions (N can be hundreds, thousands, or millions if you’re lucky) will lead you to an inconsistent state. Any 2PC framework comes with fault recovery but is not fail-proof. You will need a mechanism to detect and fix the inconsistencies (usually a script detects them and someone manually fixes them). So, I agree with the point you make that the “bad microservices – create scenario” is problematic.
However, the text suggests that: the CreateLegalEntity() method should be responsible for retrying any failed calls and cleaning up after them; that the developer of CreateLegalEntity should remember to implement checkpoints for data changes so that it can resume its work when the server is restarted. IMO it’s unrealistic to think that the developer of the business logic will create retries, fault recovery, checkpoints. All this “bookeeping” is implemented in the distributed transaction *infrastructure*.
Thus, to characterize the problem here, I would rather say something like: what if the developer of the task service didn’t set up the interaction with the other services as a distributed transaction? Even if he/she did so, what if one of the participant services (e.g., Address) or the network connection becomes indefinetely (i.e., for a long time) unavailable after the voting phase of 2PC?
5) The text suggests this rule of thumb: “1 usecase = 1 transaction = 1 entity”. I can see “1 transaction = 1 entity” as a realistic design goal, but use cases often span more than one entity. For example, a use case for evaluating a bank loan request to buy a house (mortgage) may involve several entities: the account holder (borrower), the mortgage, the property. We may design the solution using services that interact via events and hence avoid distributed transactions, but from a business analysis point of view, it’s one use case that deals with more than one entity. So, my point is, “1 usecase = 1 transaction = 1 entity” may be a desirable situation but it’s not a rule of thumb.
LikeLike
Hi Paulo
Thanks for your comments. Here’s my attempt at a reply.
1) Your description is spot on, so I’ve changed the statement 🙂
2) 1 class = 1 service is not something I would recommend at all and I’m not sure where you found it? I recommend never creating a microservice that’s smaller than the logic+data of a single entity/aggregate (which typically will be several classes) due to issues with unnecessary coordination between services.
3) It’s taken from Pat Hellands article in relationship to unlimited scalability. In the context of my blog post it’s basically a statement saying that we should store the changes to an entity/aggregate in a single transaction within a single datastore (so you don’t have to have 2PC/XA transaction or have unnecessary events flying around).
4) I agree with regards to your description of 2PC and its challenges. The reason why I focus on the issue in this way, and focus directly on the bookkeeping the developer needs to do (when you don’t use 2PC), is because 95% of all SOA integrations I’ve seen, have NEVER used ANY 2PC (which is good) and NEVER thought about the bookkeeping they actually need to do when they do data updating SOAP/REST calls between their services. It seems many developers are completely unaware of how things can go wrong and what their responsibilities are in order to correct the problems.
Note: The remaining 4,9% also didn’t use 2PC, but instead used e.g. BPEL, events, etc. to coordinate and compensate.
5) We completely agree that all non trivial use-cases wont fit this, unless we chunk them up and find each entity’s natural consistency boundary. The point is that we should NEVER design a microservice that is smaller than this rule of thumb. We can definitely design larger services. As I get into in the later blog posts, for use-cases that cross entity boundaries (and service boundaries) we have to look into using e.g. Events (or other means) to coordinate between the services without having to use 2PC to accomplish the full business use-case.
I hope this makes my point more clear?
LikeLike