Danish version: http://qed.dk/jeppe-cramon/2014/04/22/micro-services-det-er-ikke-kun-stoerrelsen-der-er-vigtigt-det-er-ogsaa-hvordan-du-bruger-dem-del-3/
Part 1 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 2 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 4 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 5 – Microservices: It’s not (only) the size that matters, it’s (also) how you use them
Part 6 – Service vs Components vs Microservices
Text updated the 26th of June 2021
In Microservices: It’s not (only) the size that matters, it’s (also) how you use them – part 2, we again discussed the problems with using (synchronous) 2 way communication between distributed (micro) services.
We discussed how the coupling problems caused by 2 way communication combined with micro services actually result in the reinvention of distributed objects. We also discussed how the combination of 2 way communication and the lack of reliable messaging and transactions cause complex compensation logic in the event of a failure.
After a refresher of the 8 fallacies of distributed computing, we examined an alternative to the 2 way communications between services. We applied Pat Hellands “Life Beyond Distributed Transactions – An Apostate’s Opinion” (original article from 2007) / “Life Beyond Distributed Transactions – An Apostate’s Opinion” (updated and abbreviated version from 2016), which takes the position that Distributed transactions are not the solution for coordinating updates between services. Finally we discussed why distributed transactions are problematic and what approach Pat Helland proposed instead.
According to Pat Helland, we must find the solution to our problem by looking at:
- How do we split our data between services
- How do we identify our data within services
- How do we communicate between our services
Section 1 and 2 were covered in Microservices: It’s not (only) the size that matters, it’s (also) how you use them – part 2 and can be summarized:
- Our data must be collected in pieces called entities or aggregates (in DDD terminology).
- Each aggreate is uniquely identifiable by an ID (for example a UUID / GUID).
- These aggregates need to be limited in size, so that they after a transaction are consistent.
- The rule of thumb is: 1 use case = 1 transaction = 1 aggregate.
In this blog post we will look at section 3 “How do we communicate between our data / services”
How should we communicate between our services?
As we mentioned several times before, using 2 way (synchronous) communication between our services causes tight coupling on multiple levels and it’s something we should try to minimize because:
- It results in communication related coupling, because data and logic are not always in the same service
- It results in contractual-, data– and functional/behavioural coupling as well as higher latency due to network communication
- Layered coupling, because persistence is not always in the same service that uses the data and contains the logic
- Temporal coupling, because our service can not operate if it is unable to communicate with the services it depends upon
- The fact that our service depends directly on other services, undermines its autonomy and makes it less reliable
- All of this results in the need for complex logic compensation due to the lack of reliable messaging and transactions.
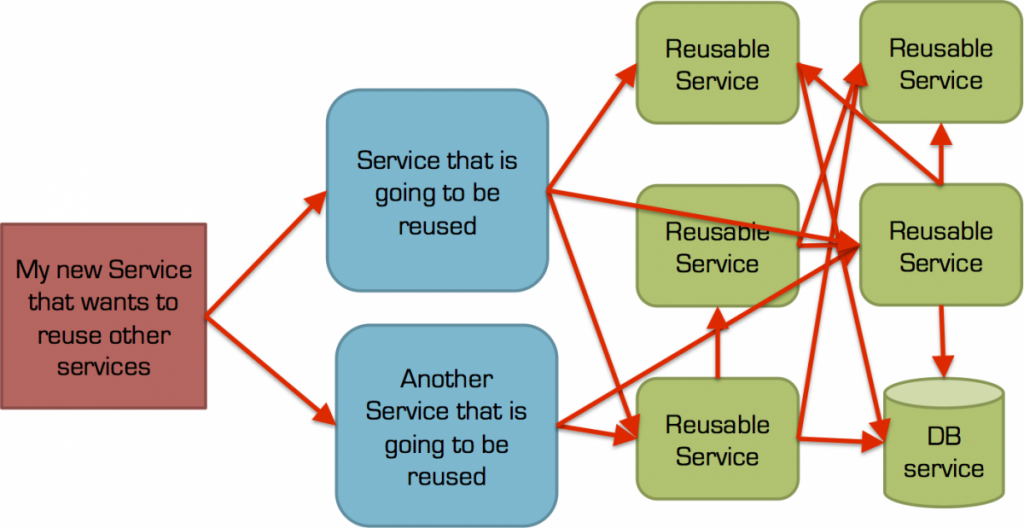
Reusable service, 2 way (synchronous) communication and coupling
If the solution is not synchronous communication, the answer has got to be asynchronous communication?
Yes, but it depends… 😊
Before we dive into the details of what it depends on, let’s first look at the characteristics of synchronous and asynchronous communication:

Based on these characteristics, we briefly categorize the forms of communication as follows:
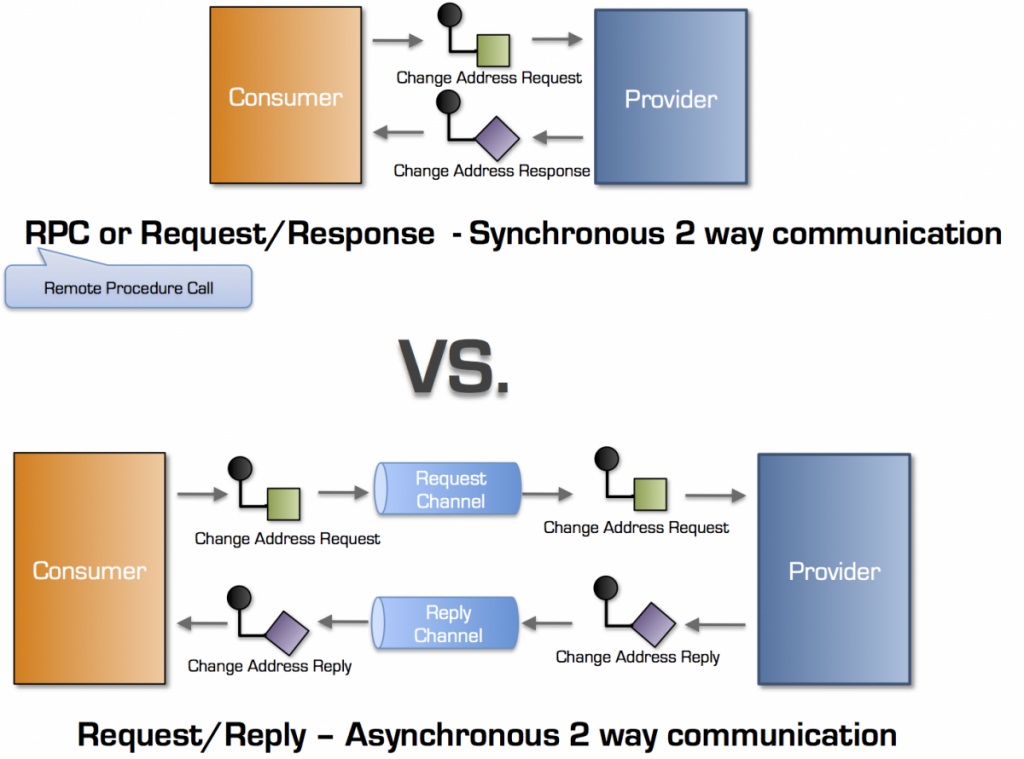
Synchronous communication is classical two way remote communication
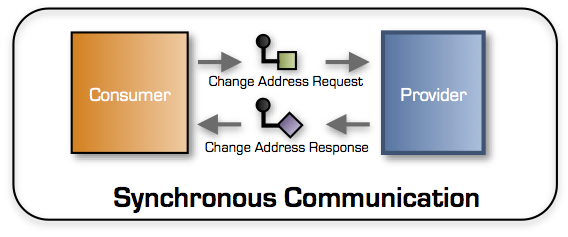
The communication pattern visualized in the drawing is called the Request/Response and is the typical implementation pattern for Remote Procedure Calls (RPC), REST and GraphQL.
With the Request/Response pattern a Consumer sends a Request message to a Provider. While the Provider processes the request message, the Consumer can basically only wait* until it receives a Response or an error
* Some might point out that consumer can take advantage of asynchronous platform features so that it e.g. can perform several calls in parallel while waiting, which allows for higher overall throughput. This unfortunately does not solve the temporal coupling issue between the Consumer and Provider – the Consumer simply cannot continue its work BEFORE it has received its Response from the Provider.
The typical execution path flow of Request / Response or RPC is visualized in the diagram below.
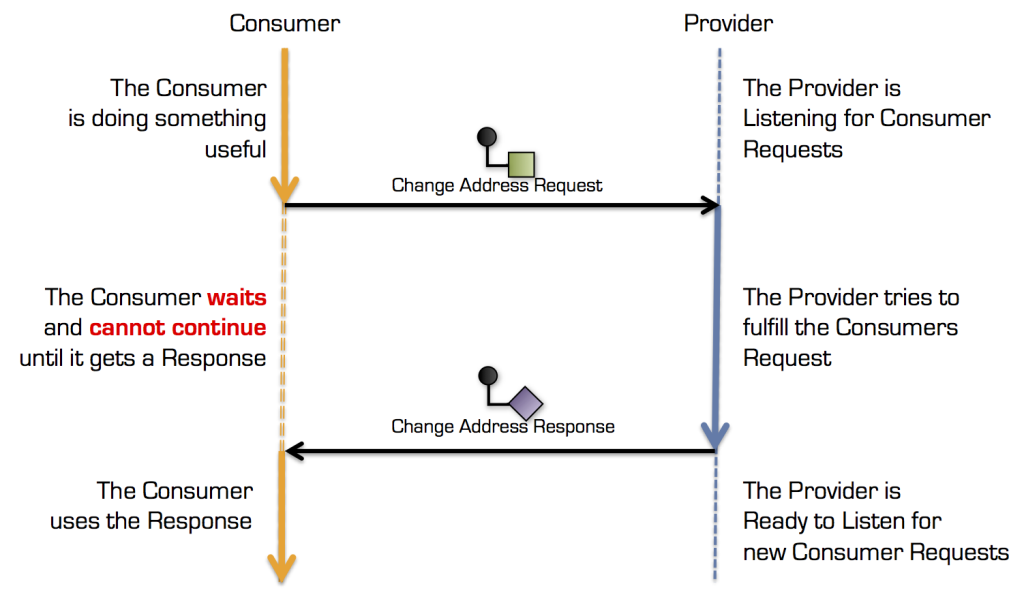
Synchronous communication flow
As shown in the drawing, there is a strong coupling between the Consumer and the Provider. The Consumer can not perform its job if the Provider is unavailable. This type of coupling is called temporal coupling or runtime coupling and is something we should minimize between our services.
Asynchronous communication is one way communication
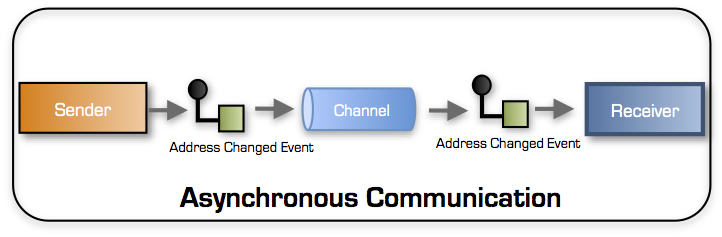
With asynchronous communication, the Sender transmits a message to a Receiver over a transport channel. The Sender waits briefly for the channel to confirm the receipt of the message (aka. a send receipt). Seen through the eyes of the Sender, the process of sending a message to the channel is a synchronous operation.
When the channel has confirmed receiving the Message the Sender can continue its work. The Sender doesn’t need to wait for Receiver to be available nor for the Receiver to process the message.
This is the essence of one way communication and the typical execution path flow is visualized below:
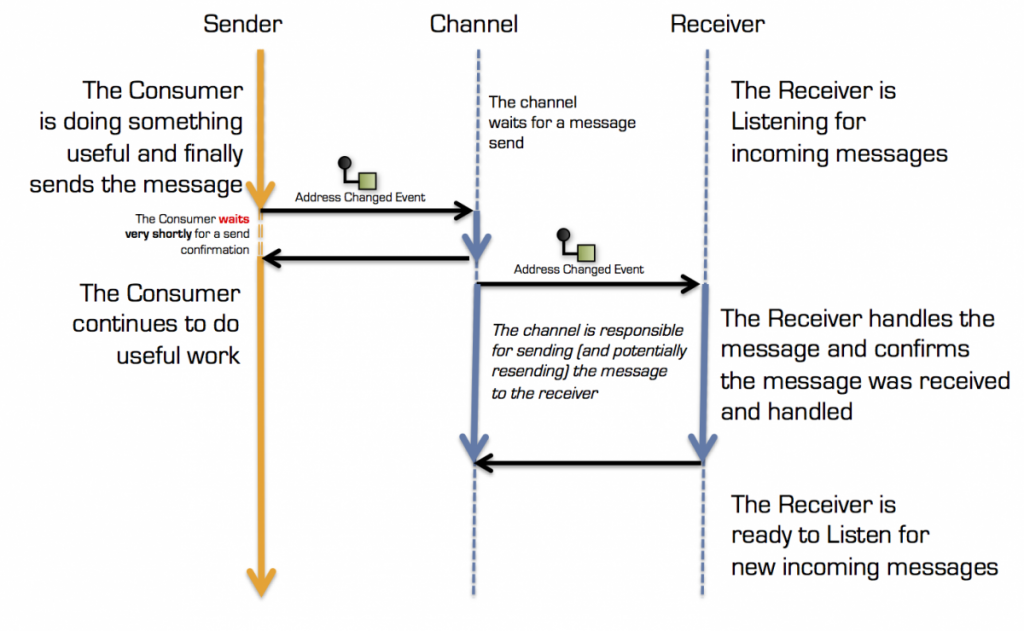
Asynchronous communication flow
Asynchronous communication is also often called messaging.
The transport channel is responsible for receiving the messages from the Sender and responsible for delivering the messages to the Receiver (or receivers). The transport channel, so to speak, takes responsibility for the message exchange. Transport channels can be both simple, such as Sockets ala zeroMQ or advanced distributed solutions with durable Queues / Topics (as e.g. supported by ActiveMQ, HornetQ, Kafka, etc.).
Messaging and asynchronous communication channels offer different delivery guarantees that govern the message exchange. This is covered in Guaranteed delivery and Guaranteed message ordering.
Why isn’t asynchronous communication the full solution?
In reality it is, but sadly it is not as easy as asynchronous versus synchronous.
The integration pattern used between our services determines the actual coupling level.
If we’re talking true asynchronous one way communication then we are on target with regards to most cases (the behavioural coupling is now determined by the type of message, where the most common types are Command messages, Event messages or Document messages.
The challenge is that two way communication comes in several forms /variations:
- Remote Procedure Call (RPC) synchronous communication
- Request / Response (e.g. REST/GraphQL) – synchronous communication
- Request / Reply – also known as synchronous over asynchronous communication.
I have repeatedly seen projects that used Request/Reply (synchronous over asynchronous) to ensure that their services were not temporally coupled. The devil is, as always, in the details.
If we have a use case where a User of our service, being it through a UI or another API, is actively waiting for the result/outcome, then seen from the Consumer, there is not a big difference in the degree of temporal coupling between RPC, Request/Response or Request/Reply, as they are all variants of two way communication that forces our Consumer to wait for a response from the Provider, before it can proceed:
So what is the conclusion?
The conclusion is that 2 way communication between services is the root of many problems and these problems are not getting any smaller by making our services smaller (nano- or micro-services).
We have seen that asynchronous communication can break the temporal coupling between our services, but ONLY if it takes place as a true one-way communication.
Our solution 🙂
The question is how do we design services (or microservices) that basically only need one-way asynchronous communication between each other*
In the next blog post we will look at how we can divide up our services and how they can communicate with each other via asynchronous one way communication, to achieve loose coupling and no temporal coupling.
* Communication between the UI and a Services is another matter, where 2 way synchronous communication is the preferred approach.
Appendix over Message guarantees
Guaranteed delivery
Guaranteed delivery covers the degree of certainty that a messages will be delivered from the sender to the receiver. These delivery guarantees are typically implemented by a reliable messaging infrastructure such as a message-queue or a topic.
At Most Once
With this delivery guarantee the Receiver will receive a message 0 or 1 time. The Sender guarantees that message is sent only once. If the Recipient is not available or able to store data related to the message (e.g. due to an error), the message will NOT be redelivered.
At Least Once
With this delivery guarantee, a message is received 1 or more times (i.e. at least once). The message will be redelivered by the channel until it has received a reception-acknowledgment from the Receiver. This means that the message can be delivered more than once and thereby processed more than once by the Receiver. Lack of acknowledgment from the Receiver can be due to unavailability or failure. Repeated delivery of messages requires additional processing logic on the Receiver side. The receivers handling of the message MUST be idempotent* to avoid any business side effect to occur more than once.
Supporting idempotence almost always** requires that there is a unique identifier / message ID in every message, which the receiver can use to verify if the message has already been received and processed.
* Idempotence describes the quality of an operation in which result and state does not change, if the operation is performed more than 1 time
** Some operations may satisfy idempotence without requiring a unique message identifier (such as Deleting an Aggregate).
Exactly Once
This delivery guarantee ensures that messages are delivered and processed exactly once. If the receiver is not available or is not able to store data related to the message, e.g. due to an error, the message will be resent until an acknowledgment of reception has been received. The difference from “At least once” is that the delivery mechanism is controlled through a coordinating protocol that ensures that duplicate messages are ignored.
Most often 2 Phase Commit is used to ensure that a message is only processed once by the Receiver. We’ve talked extensively about the challenges about 2 Phase Commit, so there’s better approach:
Another way to obtain the same qualities as Exactly Once, is to use operations that are idempotent and then combine this with the At Least Once delivery guarantee. This is the most common way to implement Exactly Once processing.
Guaranteed message ordering
Guaranteed message ordering, also known as “In order delivery” ensures that messages are received in the order they were sent. Guaranteed message ordering can be combined with above mentioned delivery guarantees.
Where guaranteed delivery focuses on delivery of each message, guaranteed message ordering is concerned with the coupling or the relationship between several messages.
Message ordering will be challenged if one or more of following circumstances occur:
- Multiple concurrent Receivers for the same Message channel will most likely cause messages to be received and handled in a different order than they were sent. Competing consumers is the most common pattern. The order in which messages are handled is now a Receiver issue as some Receivers may be faster than others. This means that a message with sequence 2 may be received by one Receiver instance AFTER message with sequence 3 was received and processed by another Receiver.
- Dead Letter Queues or Error Queues. If a message is placed on a Dead Letter Queue, or Error Queue, due to problems with delivery or handling, it gives us a challenge as to how this error should be handled and what should happen with subsequent messages until the failed message is delivered and handled.

I like your piece on one way communication. I have difficulty with the channel concept mentioned here. In what regard is a channel not similar to a micro service? Would it not have been simpler to combine the channel behavior into the receiver?
The sender uses a synchronous call to deliver its event. See the third diagram. It could this just as easily to the receiver. So the change address event goes straight to the receiver which does not act on the event by changing its entity but first confirms the receipt of the event. Internally it can subsequently proces the event and send its own event, I.e. I-changed-the-address event.
LikeLike
The channel is an abstract concept, which can be backed by several different implementations.
Classically the channel would be supported by a Queue (1-1 messaging) or a Topic (1-m messaging) which is support by e.g. JMS. This concept is know as a smart pipe with dumb endpoints. The opposite of this is smart endpoints and dumb pipes, which is what I believe you’re talking about.
For 1-1 asynchronous messaging, with reliable message delivery (i.e. at least once delivery), I would not call directly from the senders active thread to the receiver. The receiver could be unavailable and I don’t want to burden my senders business logic concerns such as retries and durability. I also don’t want to render my own service unavailable just because the receiver is down.
Instead I would hand off the message to a component inside my service that is responsible for sending messages reliably. This component could delegate the responsibility to e.g. a JMS queue (or MSMQ queue). Or it could store the message in some durable way (e.g. on the file system, a database/document store, etc.) and then it self read the message from there, attempt to deliver it to the receiver (on another thread) again and again until the receiver acknowledges the message as being received and handled.
I hope this make it more clear?
/Jeppe
LikeLike
So, what is the lesson? How they can communicate with each other via asynchronous one way communication?
LikeLike
For many integration cases one way communication will result in a much looser form of coupling (which of course is also associated with a certain cost).
In Part 4, which has just been posted, I go deeper into how we can use one way communication to integrate service and drive our business processes.
I hope it answers why one way communication would be something worth considering.
LikeLike
Just followed up on part 4. It does indeed. We are actually looking at a couple of architectural tweaks as a result.
Very good series. Kudos!
LikeLike
Another great post, raising the key question at the end. I have a few comments:
1) The text says “The challenge is that two way communication comes in several forms”. The problem is that the three bullets that follow are not three forms of two-way communication. From an architectural perspective, the generic connector in discussion here is called request/response, aka request/reply, aka call-return. Then there are variations, which are orthogonal: (i) the interaction may be local (e.g., in-vm method call) or remote (e.g., RPC, SOAP request-response MEP); (ii) the caller always wait for the conclusion of the callee, but it may or may not be blocked; (iii) the interaction may be implemented via a mechanism that is natively synchronous (e.g., in-vm method call, SOAP request-response MEP) or it may use sync over async.
2) The Appendix about message guarantees fails to explain that these guarantees are typically implemented by some reliable messaging infrastructure. I wouldn’t expect the developer of the business logic to implement these guarantees. But I’d expect the architect of the solution to know what guarantees are appropriate for a particular service consumer-provider interaction, and how to set it up in the infrastructure and in the business logic (e.g., idempotence for at-least-once).
3) Your description of idempotence will be more precise if you remove the word “even”, because state may change the first time the operation is performed.
LikeLike
Hi Paulo
Thanks for your comments 🙂
1) I was hoping it was clear that I was talking purely about remote communication (in the light of service to service communication). You’re right, they are all synchronous (i.e. the caller waits) – and forms is probably not the right name to describe the names of the different communication patterns.
2) I’ve added a comment about this. Thanks.
3) Thanks, I’ve removed “even”.
LikeLike
Doesn’t Request/Reply remove temporal coupling as long as the consumer either:
1) Persists any information about the ongoing conversation, then continues on to the next task it must perform. It may die and restart however many times, but at some point it processes the reply.
2) Relies on the guarantees of the channel/provider to handle the request, and keeps no state regarding the request. In this case, the reply must have enough information for the consumer to continue processing, but again it does not matter when the reply is received.
LikeLike
Hi Chris,
1+2) It sure does 🙂
The reason why I included request/reply (sync over async) here was in the context of service to service integration where you have a user waiting on the other end for a response.
In case we have a user waiting for a response (e.g. in a browser) doing request/response (sync) or request/reply (sync over async) has the same level of temporal coupling.
If you don’t have a user waiting directly (e.g. for a page to render the response) and you can’t avoid having to split the business task between two or more services, then request/reply is a very useful pattern for e.g. delegating a (long running) sub-task to another service. Sometimes request-reply is the right pattern, other times a Command->Event or an Event->Event pattern will make more sense because it aligns better with the nature of the business issue – see blog post 5.
LikeLike